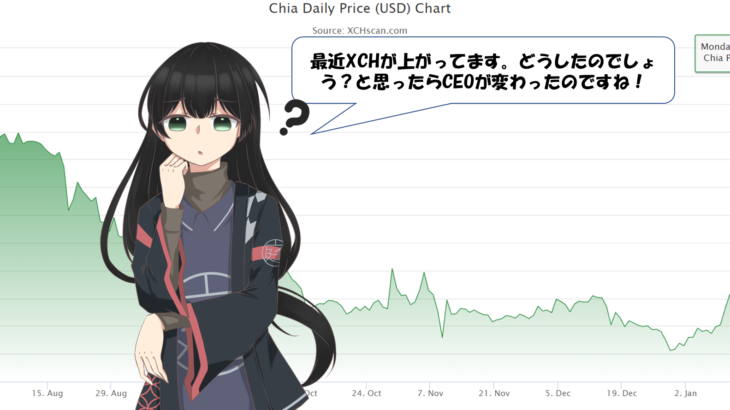
最近XCHが上がってたので調べてみました。CEOが変わったのですね!
BitTorrentのBram Cohenさんから、PGPのGene Hoffmanさんへ。

そして、「株式上場準備している!でも2023年じゃ無い」と言っているようです。これで上がってたのですねぇ。
Chia HPもリニューアルされてました。
そして、3本のブログ記事があrました。読んでおいた方が良さそうです。

圧縮plotは同じk=32で15%~30%取得が増え、GPU PlotはRTX3090 or RTX4070Tiで80秒plotが可能になるようです。GPU Plotがこなれてきたら少しずつ圧縮plotに置き換えようかなぁ、とおもうところ。いまやPlotting PCはBlender、VRChat PCととして活躍中なので、あんまりplotしたくないのが現状でもあります。
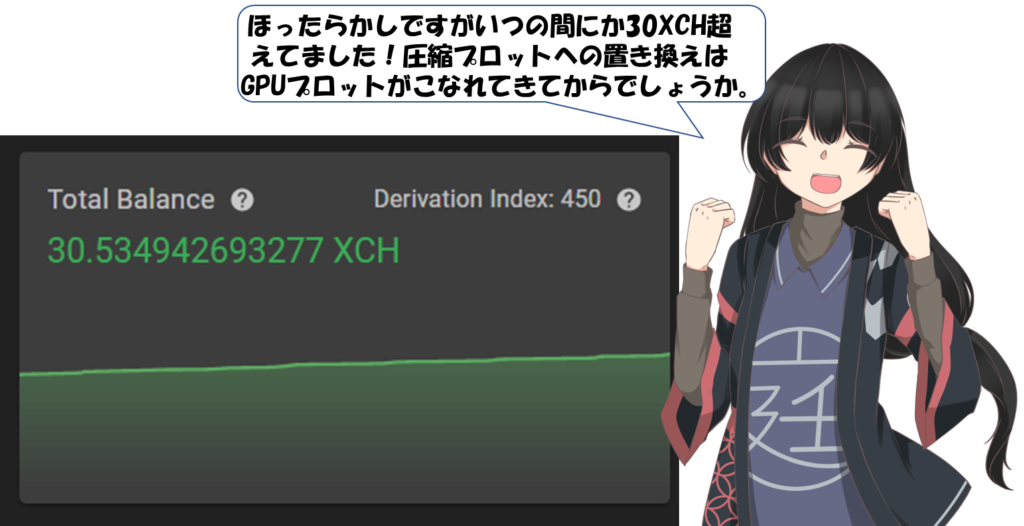
おっ、いつの間にか30XCH超えてました。
ブログの日本語訳、つけておきますねぇ。
GPU プロッティングはリアルで非常に高速
とJMハンズ、 – 2023 年 1 月 20 日
概要
- GPU プロットは、Chia と madMAx によるもので、非常に高速です。単一のハイエンド GPU + 256 GB の RAM で、1.5 分で K=32 プロット。
- GPU のパフォーマンスと I/O 帯域幅は急速に拡大しています
- フェーズ 1 が 28 秒未満になると、理論的には GPU を使用したプロット グラインド、スプーフィング プロットを実行できますが、経済的ではなく、多くの継続的なエネルギーを必要とします。
- Chia のブロックチェーンには、陰謀のすりつぶしを防ぐための定数が設定されています。正直なプロット作成者を傷つけることなく、プロットの粉砕に対する究極の保護は、それを不経済に保つことです
- Chia は、プロット フィルターを減らしてプロット グラインドが予見可能な将来にわたって非経済的であることを保証するための CHIP を提案しています。
はじめに
GPU プロッティングは現在、いくつかのコミュニティ プロッターが実際に使用されており、非常に高速です。PCIe 4.0 x16 ハイエンド GPU (RTX 3090 または 4070 Ti) で 80 ~ 90 秒の単一プロット時間を確認しています。これは、CPU (Intel の新しい第 4 世代 Xeon スケーラブル プロセッサ) で記録された単一最速プロット時間の約半分です。 、コードネーム サファイア ラピッズ)。GPU は最上位のサーバーよりもはるかにアクセスしやすく、大幅に安価であるため、これは素晴らしいことです。また、プロットは通常、プロセス全体の中で最も難しい部分の 1 つであるため、この開発により Chia 農業への参入障壁が減少します。 . GPU プロットは、プロットのエネルギー消費も最大 3 分の 1 に削減します。ak=32 の一時メモリ要件は基本的に変わりませんが、非圧縮フェーズ 1 のプロット用に約 256 GB の一時ストレージが必要です。
これらの GPU プロッターのほとんどが動作する方法は、CPU プロッターが動作する方法と同様に、テーブルを取得してバケットに分割し、それらのバケットを GPU に渡して、プロット フェーズで必要な並べ替え、マッチング、および圧縮機能を実行することです。 . GPU 実装は、最新のカードでこれらを実行する際に実際には非常に高速であり、リミッターは生の GPU パフォーマンス、PCIe 帯域幅、またはメモリ帯域幅のいずれかになります。DRAM の量が少ないと、一時ファイルにオフロードするためにディスク io が必要になり、これがパフォーマンスのボトルネックになり、プロセスが 2 倍から 3 倍遅くなりますが、プロットではデスクトップ CPU よりもはるかに高速です。
GPU のパフォーマンス
GPU は、GPU 計算ユニットの量の増加とシリコン自体の電力効率のおかげで、世代を追うごとに高速化しています。最新世代の NVidia 4090 カードは、3090 のほぼ 2 倍のコンピューティング能力を備えており、2016 年から 2022 年の間に 25% のパフォーマンスの平均 CAGR (複合年間成長率) を達成しています。

PCI Express (PCIe) は、コンピューティング、ストレージ、およびネットワーク用の高速コンポーネント向けの主流の汎用 I/O 相互接続です。また、高性能 SSD により、CXLは現在、キャッシュ コヒーレント メモリ拡張、アクセラレータ、AI、および 400Gbs ネットワーキングのために PCIe Express バスに移行しており、非常に高速になっています。PCI-SIG は、I/O 帯域幅が約 3 年ごとに 2 倍になると予想しています。PCIe 5.0 デバイスが登場しており、DDR5 メモリのいくつかのチャネルと同様に、x16 リンクが各方向で 64GB/s を実行できます。

たとえば、無限のコンピューティング能力と完璧なソフトウェア効率があり、PCIe 帯域幅によってのみ制限されるとします。プロットのフェーズ 1 を完了するには、約 500 GB のデータを GPU にダウンロードし、約 360 GB をホスト CPU に送り返す必要があります。これにより、PCIe 4.0 x16 カードの理論上の制限は約 20 秒、PCIe 5.0 x16 カードの理論上の制限は 10 秒になります。POC を使用すると、PCIe 4.0 GPU でフェーズ 1 に必要な正確な量のデータを転送するのに、実際には約 24 秒かかります。PCIe 仕様がリリースされてから、大量生産部品を出荷する多くのベンダーにかかる時間は、通常、約 3 年です。PCIe 5.0 の基本仕様は 2019 年にリリースされました。現在、AMD と Intel の両方がコンシューマ プラットフォームと最近発売されたサーバー プラットフォームで PCIe 5.0 をサポートしていることがわかります。SSD などの最初の PCIe 5.0 デバイスは、

より安価で効率的なプロット
GPU を使用すると、CPU を使用した以前の最も効率的なメモリ プロットよりも 2.5 倍効率が高く、デスクトップ プロットよりも 5 倍効率的です。プロットされたテラバイトあたりのエネルギー (kWh) でプロット効率を測定しています。これは、農家が自分たちのスペースをより速く作図し、作図のための電力コストを削減し、作図のための世界的なエネルギー消費を削減できることを意味します。
以下に例を示します
- AMD 5950X、PCIe 4.0 x16、128GB DDR4、2x 980 Pro NVMe、3060Ti
- 作図時265W
- 4分 k=32
- 1 TB あたり 0.2kWh で 31.4 TB/日
- 200 TB を再プロットするための総コストは 6.37 日と 5.67 ドル

こちらのスプレッドシートで、再プロットの推定コストとエネルギーを比較できます。
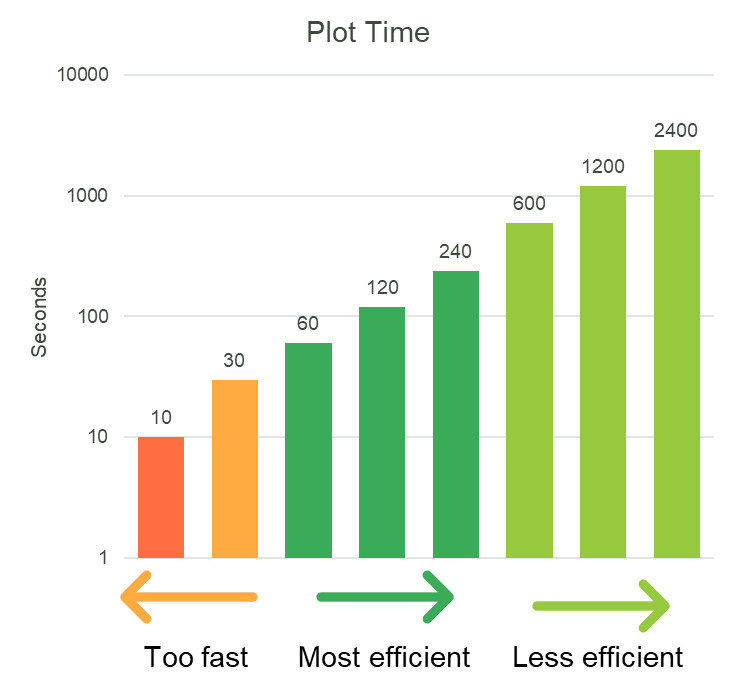
ちょっと速すぎる – プロットの研削
標識ポイントが解放された後にプロットの作成を開始し、注入ポイントの前にプロットを完了しようとすることができます。これについては、Chia docs サイトで詳しく説明されています。次に、品質評価を取得した後 (または資格がある場合は校正を提出した後)、プロットを削除します。これにより、フィルターを自動的に通過するプロットを作成できるようになり、スペースを保存せずに効率的に農業を行うことができます。これは、プロットのフェーズ 1 が 28 秒以内 (注入前) に完了できる場合にのみ実現可能になります。これは、セキュリティ リスクをもたらすネットワークへの攻撃ではありませんが、スペースの代わりにコンピューティングを使用しようとする試みにすぎません。これを「プロットグラインド」と呼んでいます。
プロット フィルターを通過するプロットを 28 秒以内に作成できるとします。これは、1 * プロット フィルターのプロット数から、見落とした 2 つの標識ポイントを引いたものと同じです。GPU が最初の課題を解決しようとしている間は、他の課題を無視する必要があります。これにより、1/3 * プロット フィルター定数のレバレッジ ファクターが得られます。レバレッジ係数は、スプーフィングされているプロットの数に相当するため、スプーフィングされたスペースの量を TiB または TB で簡単に計算するには、ak=32 プロット サイズを掛けます。プロットの研削に必要なフェーズ 1 には適用されないため、圧縮の二重浸漬はありません。
プロットが 18.75 秒未満で作成されると、真の効果が発揮されます (現実的には、フィルター処理などのオーバーヘッドが数秒かかるため、実際にはおそらく 15 秒程度です)。3 つのサイネージ ポイントのうちの 1 つを見逃しているため、このレバレッジはプロット フィルターの 2/3 * のように見えますが、トリックがあります。2 番目のサイネージ ポイントで、プロット ID を作成し (多くの BLS キーを作成することによって)、最初と 2 番目のチャレンジの両方のフィルターを通過できるプロットが生成され、フィルターを通過するための両方の基準を満たす SHA256 フィルター ハッシュにそれらを配置します。時間 t[2] で、フィルターがチャレンジ 1 と 2 (c1 & c2) を通過するものをプロットし始め、時間 t[4] で c3 と c4 を通過します。このトリックは、サイネージ ポイント タイム 9.375 秒未満でフェーズ 1 を取得するように拡張できます。ハッシュが 3 つのフィルターすべてを通過する基準 (現在は 512^3) を満たすプロット ID が作成された場合、3 つのチャレンジすべてを試すことができます。ありがたいことに、現在このようなことを実行するには、非常に大規模な GPU クラスターと膨大な量の電力が必要であり、レバレッジを拡大しても経済的ではありません。
| フェーズ1回 | プロット フィルタ | レバレッジ係数 (プロット) | スプーフィングされたスペース (TiB) |
| > 28.125 秒 | 512 | なし | 0 |
| 28.125 | 512 | 171 | 16.9 |
| 18.75 | 512 | 512 | 50.7 |
| 9.375 | 512 | 1536 | 152.0 |
| t < 9.375 | 512 | 9.375/トン×3または3.5 | プロット * 101.3GiB / 1024 |
表 1: グラインド レバレッジとスプーフィングされたスペース対プロット時間のプロット
現在、フィルターは 512 プロットであるため、これらをスプーフィングすると、約 55 テラバイトのストレージになります。これの収益性は、55 テラバイトの正直なスペースを持つこととまったく同じですが、これには、より多くのハードウェア コスト (設備投資) と、非常に多くのエネルギーが必要です! 55 テラバイトは、それぞれ 5.6W の 18TB ハード ドライブ 3 台で、合計 16.8W です。ミッドレンジ GPU は 150 ~ 200W に加えてプラットフォームの電力 (マザーボード、CPU、DRAM) を消費し、単一の GPU システムを実行中のディスクの約 20 倍の電力にします。
研削経済学のプロット
Chia ファーミングやその他の暗号通貨マイニングと同様に、総所有コスト (TCO) モデルはコストを理解するのに役立ちます。プロット グラインドを試みるために必要な機器は、ワークステーション プラットフォーム、256 GB の DRAM、および複数の PCIe 4.0 GPU であり、コストは簡単に見積もることができます。プロット作成の速度によって、偽装できるスペースの量が決まります。次に、Netspace と xch の価格が収益性を提供できます。
GPU が既に所有されている場合、電力コスト (運用コスト) が唯一のコストになります。スプーフィング能力の収益性は、実行するための電気代よりも大きくなければなりません。
PCIe x16 スロットを備えたデスクトップはすぐに安価に入手できるため、単一の GPU で利益を上げて実行できる場合、プロットの粉砕は Chia にとって本当に懸念されます。PCIe 4.0 をサポートするサーバーとワークステーションは、デスクトップに比べて依然としてかなり高価です。他のコインのほとんどの GPU マイナーは、これらのセットアップをすぐに利用できません。
プロット研削スプレッドシートはこちら
プロット フィルター
プロット グラインドは、PoST を PoW に変える試みです。ありがたいことに、Bram はこれを予期しており、Chia にはこれを防ぐための多くの定数があります。Chia で選択された重要な定数は、ブロック時間、ネットワーク上の最小 k サイズ、およびプロット フィルターです。これからの最も重要な保護は、プロットに多くのリソースと時間を必要とすることによって正直なプロッターを傷つけることなく、それを信じられないほど不採算で経済的でないものにすることです. 収益性はプロット フィルタに比例します。プロット フィルターの削減により、今後数年間、プロット グラインドが即座に実行不可能になります。
プロット フィルターが農業でどのように機能するかを思い出してください。
- ファーマーが VDF からチャレンジを受ける
- ファーマーはサイネージ ポイントをハーベスターに送信します
- Harvester はプロット フィルタを適用して、ディスクで必要な I/O を削減します (1/512)
- フィルタを通過したプロットの場合、ハーベスタはプルーフ品質チェックを実行します
- 品質が(困難から)必要な反復を満たしている場合、スペースの証明は良好です
- プルーフ オブ スペース全体を取得する
plot filter bits = sha256(plot_id + challenge_hash + sp_hash)フィルターは、ディスク I/O の削減に非常に効果的であり、ファーミング ストレージ ワークロード分析は、ディスク ファーミング Chia が 99.75% アイドル状態であり、0.5 IOPS しか消費しないことを示しました。これは、最新のハード ドライブのランダム シーク機能の約 350 分の 1 です。512 という定数は、農業を可能な限りエネルギー効率的にするために保守的に設計されました。プロット フィルターの唯一の欠点は、プロットが作成される前にプロット フィルターを計算できるため、プロット グラインドに影響を与えることです。フィルターが 2 倍または 4 倍減少すると、ディスク io が同じ係数だけ増加しますが、これは最新のハード ドライブ ファーミングでは問題になりません。ただし、フィルターはプロット圧縮と独自の相互作用を持ちます。フィルターを通過するすべてのプロットは、スペースの完全なプルーフを取得する前に解凍ステップを経る必要があり、プルーフ品質チェック中に欠落した一致がその場で生成されるためです。フィルターを減らすと、フィルターを通過するプロットが増加します。
設計により – PoST のエネルギー効率を維持する
PoST には、プロットのグラインディングを防ぐことができる多くのノブがあります。ネットワーク上の最小 k サイズ (現在は 32) の変更、プロット フィルターの削減、Chia プルーフ オブ スペースへのプロット テーブルの追加、および Chia プルーフ オブ スペース アルゴリズムの完全な変更を評価しました。ここでは他の提案については説明しませんが、オプションを徹底的に分析しました。
まとめ: プロット フィルターを徐々に減らして、プロット グラインドが経済的に実行可能にならないようにすることをお勧めします。
行は影響を与えようとしている基準で、列は実装できるプロトコルの変更です。これは、ブラムと私がこの陰謀の問題をどのように考え抜いたか、そしてそれを防ぐために調整できるプロトコルの変更を人々が学ぶためのものです.
Bram & JM の理論的根拠。
| 提案 1: フィルタ削減 | 提案 2: k を増やす | 提案 3: プロットのグループ化 | 提案 4: テーブルを増やす | 提案 5: 収穫の強化 | |
| 経済プロット研削 | 比例 | 比例 | 比例 | 多分小さな改善 | 無効 |
| 51% 攻撃プロット グラインド | 比例 | 比例プラスしきい値 | 比例 | 多分小さな改善 | 無効 |
| 正直なプロットコスト | 無し | 比例 | 無効 | 重要 | 無効 |
| 必要な再プロット | 無し | はい | はい/いくらか | はい | 無効 |
| 正直な収穫コスト | 比例 | 番号 | 無効 | 微増 | 小さな改善 |
| カスタム プロットの利点 | 番号 | はい | 無効 | 微増 | 無効 |
| カスタム収穫の利点 | はい (例: GPU) | 番号 | 無効 | 質的改善 | 著しい向上 |
| ハードフォーク | はい | 番号 | 番号 | はい | 番号 |
| 最小プロット サイズ | 無効 | 比例 | 比例 | 増加 | 無効 |
フィルタ削減: フィルタの効果的な半減ごとに、プロット グラインドの実行可能性が比例して減少します。フィルターを下げると、ディスク io (既に非常に低い) とプロットの解凍 (ハーベスターの CPU/GPU サイクル) に影響します。
K サイズの増加: 制限を k=33 に引き上げ、コンピューティングの改善に対応するために 2 ~ 3 年ごとに増加します。
新しいプルーフ オブ スペース (テーブルの増加、プロットのグループ化) : プルーフ オブ スペース フォーマットまたはコンセンサスの大幅な変更: プルーフ オブ スペースの研究中に、多くのプロット フォーマットが評価されました。現在の Chia プロット形式は、その 2 年間の研究の最高のものを表しています。プルーフ オブ スペースをペアにすることや、表の数を増やすためにプロット形式を変更することなど、コンセンサス オプションがあります。これらのどちらも、フィルターや k 値などの定数を変更した場合の影響の大きさは同じではありません。
収穫の強化: 減圧を収穫者ではなく農家に移します。
基準
- 経済的なプロット グラインディング : xch の報酬は有効なスペースに応じてスケーリングされるため、より少ないプロットをスプーフィングすると、プロット グラインディングの収益性が比例して低くなります。
- 51% 攻撃のプロット グラインド: プロット グラインドを介してネットワークを 51% にするには、非常に高価で実行不可能 (利用可能なリソースが十分でない) にします。
- 正直なプロット コスト: プロットの作成に必要な物理的な計算、メモリ、およびストレージ リソースを削減します。プロットの効率 (エネルギー利用、時間) はリソースの使用に比例し、主に最小 k サイズによって決まります。
- 必要な再プロット: 変更には古いプロットを無効にする必要がありますか ?
- 正直な収穫コスト: 変更により、収穫と農業により多くの資源とエネルギー消費が必要になりますか?
- プロッティングのカスタムの利点: カスタム ソリューションは、通常のプロッタよりも大幅な利点を提供しますか?
- ハードフォーク: ネットワークとの下位互換性のある変更です。現在のコンセンサスで何かが有効ではなく、それを有効にする場合、これにはハードフォークが必要です。
- 最小プロット サイズ: 理想的には、より多くの参加者にインセンティブを与えるために、ネットワークのセキュリティに影響を与えずにファイル サイズをできるだけ小さくする
概要
Chia ネットワークでの GPU プロットが登場し、従来の CPU プロットよりもはるかに高速で効率的になりました。これにより、作図のエネルギー消費が 2 ~ 5 分の 1 に削減され、農家の作図時間が大幅に短縮され、Chia への参入障壁が減少し、分散化が進みます。GPU のパフォーマンスと I/O 帯域幅は急速に増加しており、将来の GPU は 28 秒未満でプロットのフェーズ 1 を実行できるため、経済的/収益性は高くありませんが、プロット グラインドが可能になります。しかし、Chia ブロックチェーンにはプロット グラインドを防止するための定数が設定されており、将来的にプロット グラインドの収益性をさらに下げるために CHIP を提案します。
プロット フィルターの CHIP の紹介
理論的には、全帯域幅の PCIe 4.0 x16 GPU を 2 つ、または PCIe 5.0 GPU を 1 つ使用して、プロット グラインドを試みることができます。後者は、AMD または NVIDIA からまだ入手できません。プロット フィルターを変更して、プロット グラインドが経済的に成り立たないようにすることをお勧めします。
プロット グラインド、プロット フィルター、およびその提案された削減は、新しく提案されたCHIPで概説されています。
プロット圧縮はこちら
とJMハンズ、 – 2023 年 1 月 20 日
概要
- プロットの圧縮は、複数の関係者から利用できるようになりました。Chia は、ベータ プログラムSoon™ を通じてサポートをリリースします。
- Chia は、空間の証明が無限に圧縮できないように設計しました
- プロットの圧縮は「時空間」のトレードオフで機能し、プロットの一部を削除して、ファーミング中にその場で再作成します
- 設計上、Chia は収益が減少するため、PoW にはなりません。プロット サイズの減少は線形であり、パワーの増加は指数関数的です!
- 農業従事者は、選択した圧縮レベルに比べて、エネルギー使用量がわずかに増加することを期待できます。

プロット圧縮を可能にする新しいバージョンの Bladebit プロッタをベータ プログラムで間もなくリリースします。これを開発するために多くの深夜を費やしてくれた Chia の Harold Brenes に特に感謝します。新しい圧縮プロットには、現在のプロットと同じ数のプルーフが含まれますが、必要なスペースは少なくなります。どれくらい少ない?これは圧縮レベルによって異なりますが、節約は 15% から 30% の間になります。この圧縮は、スペースと計算の間のトレードオフにより可能になります。
プロットの圧縮は、常にオプションです。圧縮されたプロットを使用するかどうか、および使用する必要がある圧縮のレベルの決定は、この記事の後半で説明するいくつかの要因に帰着します。
すぐに、圧縮が高くなるにつれて利益が減少することがわかりますが、最初に、一歩下がって、PoST のプロットがどのように機能するかを更新しましょう。
PoW 対 PoST
PoW (Proof of Work) は、ビットコインなどのブロックチェーンを保護するためのアルゴリズムです。PoW では、マイナーと呼ばれるコンピューターがハッシュと呼ばれる乱数を継続的に生成します。これらのハッシュは宝くじのように機能します。当選した宝くじが見つかると、マイナーは新しいブロックを作成して報酬を受け取り、プロセスが最初からやり直されます。Proof of Work は最初のNakamoto Consensusであり、とりわけ、特定のブロックチェーンが標準的なものであることを簡単に検証できます。
PoW は、参加する各マイナーが勝利のチャンスを最大化するために継続的にハッシュを生成する必要があるため、エネルギーを大量に消費します。もちろん、ほとんどのハッシュは勝てません。それらは、宝くじをなくしたようなものです。廃棄され、二度と見られなくなります。
PoST (Proof of Space and Time) は、2 番目で唯一のナカモト コンセンサスです。PoW と同様に、宝くじのように機能するハッシュを使用します。主な違いは、PoST では、宝くじを一度生成するだけでよいことです。1 回の使用で廃棄する代わりに、農家はそれらをplotと呼ばれるファイルに保管します。各区画には 40 億枚以上の宝くじが含まれていますが、区画がどのように編成されているかにより、農業用コンピューターが当選券を取得するために必要なリソースは最小限です。そして何よりも、プロットはディスクの存続期間中再利用できます。
PoST コンセンサスにより、Chia のブロックチェーンは、ネットワーク全体の消費電力の 1% 未満を消費しながら、Bitcoin と同様のレベルのセキュリティを実現できます。
プロット圧縮の概要
Chia プロットの作成中に、必要な一時ストレージの量がプロットの最終サイズよりも大きくなります。プロットのフェーズ 1 の後、プロットは技術的には耕作可能ですが、可能な限り最小の形式では表現されません。プロット プロセスの後半のフェーズでは、Chia プロット フォーマットに固有のアルゴリズム圧縮を実行します。この圧縮は、プロットのデータを 100% そのまま維持しながら、最大限に効率的になるように設計されています。つまり、元のプロット形式は既に圧縮されています。
プロットをさらに圧縮するにはどうすればよいでしょうか?
この新しい圧縮は、計算とストレージの間のトレードオフから生まれます。プロットのデータを 100% 保存するのではなく、その場で計算できるものもあります。プロットから省略されるデータが増えると、ハーベスタは証明を取得するためにより多くの計算を実行する必要があります。
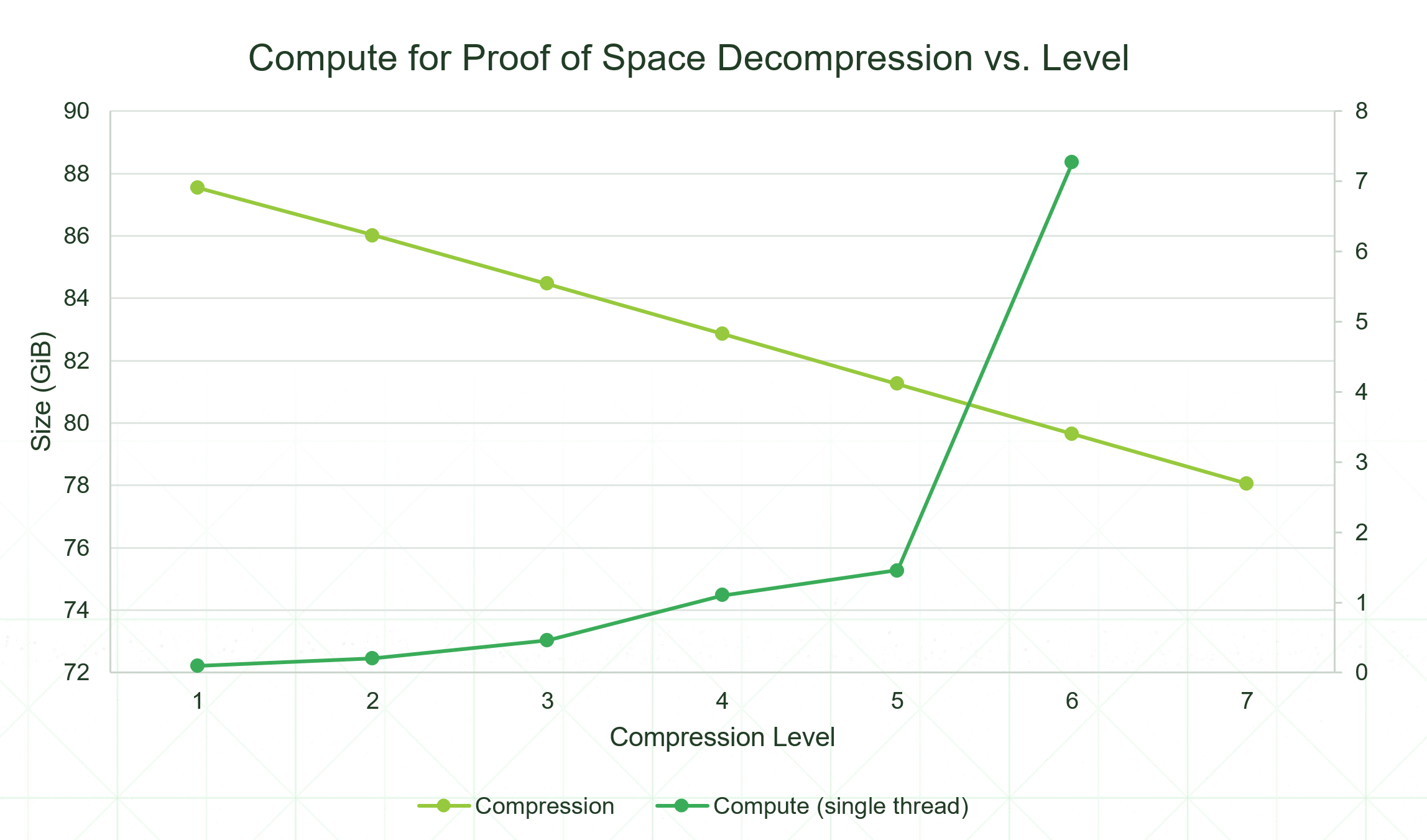
プロット圧縮のレベルを、0 (圧縮なし) から 7 (高圧縮) までの単純な数値にまとめました。圧縮レベルが上がるごとに、結果として得られるプロットのサイズが直線的に減少しますが、その代償として、ファーミングに必要な計算能力が指数関数的に増加します。
| 圧縮レベル | プロットあたりの GiB | GB/プロット | % 割引 | % 変更報酬 |
| 0 | 101.30 | 108.77 | 0 | 0.00% |
| 1 | 87.54 | 93.99 | 13.61% | 15.72% |
| 2 | 86.03 | 92.37 | 15.10% | 17.75% |
| 3 | 84.46 | 90.69 | 16.64% | 19.93% |
| 4 | 82.86 | 88.97 | 18.23% | 22.25% |
| 5 | 81.26 | 87.25 | 19.81% | 24.67% |
| 6 | 79.65 | 85.52 | 21.39% | 27.18% |
| 7 | 78.05 | 83.81 | 22.97% | 29.79% |
表 1. 圧縮レベルとプロット サイズ
既存のプロット形式を使用したファーミングでは、ごくわずかな計算リソースしか必要としません。プロットをレベル 1 に圧縮すると、サイズが 13.61% 縮小され、農業の報酬が 15.7% 増加しますが、追加の処理能力はほとんど必要ありません。現在のレベルは、ビット ドロップが直線的に減少していることを示しています (たとえば、レベル 1 は 16 ビット、レベル 2 は 15 ビット) が、解凍の計算は指数関数的に増加しています。それでも、指数計算はすぐに追いつくため、特定のポイントを超えると実用的ではなくなります。プロット パラメーターを調整することで、さらにレベルを追加できます。将来的には、オプションの GPU ハーベスティング、より効率的なアルゴリズム、およびプルーフ品質チェックのオフロードにより、合理的なオーバーヘッドでさらにいくつかのレベルを許可できるようになります。機能強化が書かれると、
何ヘルマン?Chia空間証明における時空間トレードオフ
Chia Proof of Space 形式のアイデアの背後にある元の論文、Beyond HellmanおよびChia Proof of Space Constructionは、「時間空間のトレードオフ」の有効性を減らすように設計された「プロット テーブル」の概念を文書化しています。
反転するのにより多くの時間および/またはスペースを必要とすることが証明されている関数を構築します。
Chia では、計算サイクルではなく、ディスク領域をブロックチェーン コンセンサスのための希少なリソースにしたいと考えています。プロットは、プロットごとに 1 回だけ実行する必要があるため時間がかかる場合があり、証明 (農業と収穫) は迅速かつ効率的である必要があります。Chia は、これが実際にHellman Attackでどのように機能するかについて、メインネットの立ち上げ前にいくつかのサンプル コードをリリースしました。テーブルをプロットする Chia では、これらの時間空間 (または計算 / 空間) を実行することは、テーブルをたどるにつれて指数関数的に難しくなります。Bram は、スペース ルックアップの完全な証明に必要なディスク IO の量、時間空間のトレードオフからの保護、およびプロット時間の間の合理的なトレードオフとして、7 つのテーブルを選択しました。
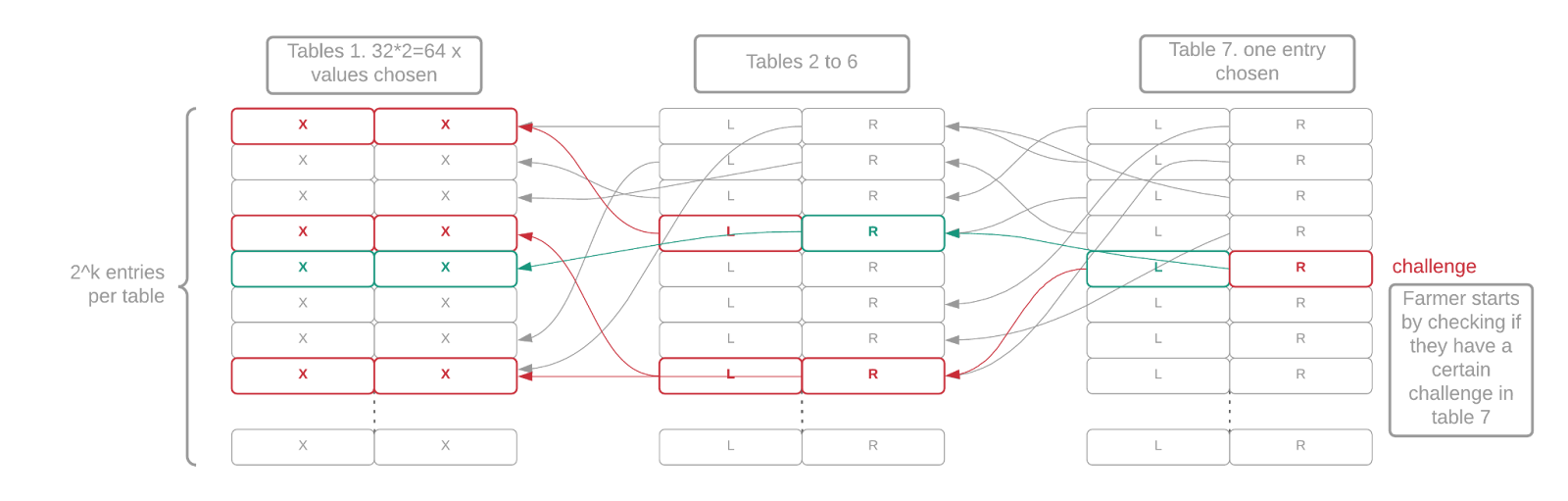
ak=32 プロットは実際にはどのように見えますか?

ビットをドロップ
101.3 GiB または 108.8GB の k=32 プロットには、約 2^32 のプルーフ (42.9 億プルーフのスペース) が含まれます。レベル 1 ~ 7 の「ビット ドロップ」と呼ばれる新しい圧縮方法では、テーブル 1 全体が削除され、バック ポインターの代わりに、テーブル 1 からテーブル 2 に削減された量のエントリが配置されます。圧縮レベル 1 は 16 ビットを使用し、ak=32 に必要な 32 ビットのうち 16 ビットのみを格納します。もちろん、スペースの証明全体を取得しようとすると、エントリの半分が欠落しているため、これは問題になります。これらはオンザフライで生成する必要があり、欠落しているエントリのすべての可能な一致を調べる計算が必要です。このトリックは、より多くのデータをドロップすることでさらに拡張できます。その後、完全なプルーフ オブ スペースを取得するときに、その場でさらに多くのデータを生成する必要があります。これは可逆圧縮の一種で、


これは、さまざまなレベルの圧縮がどのように機能するかを説明しています。各圧縮レベルは、より多くのデータをドロップすることで機能し、収集時により多くの計算を必要とします。オンザフライでデータを作成するために必要な計算サイクルは、必要な計算量が完全なプロットに達するまで指数関数的に増加します。現在、Chia 圧縮レベル 7 は区画サイズを 23% 縮小します。つまり、ファーマーは、農業中に余分なエネルギーを犠牲にして 29.8% 多くの報酬を得ることが期待されます。
時間と空間のトレードオフでは、プロット サイズは直線的に減少しますが、ファーミングに必要な計算は指数関数的に増加します。
ありがたいことに、設計上、チア ファーミングはプルーフ オブ ワークに比べて少量のエネルギーを消費します。より高いレベルの圧縮を行っても、ほとんどの農業従事者のエネルギー消費量は 20 ~ 25% しか増加しません。このプロセスを繰り返し強化し、効率を高めています。指数関数的なスケーリングにより、農家は膨大な量のエネルギーを消費して不当な優位性を得ることができなくなります。
より多くのスペース – 実効容量の紹介。
実効容量は TBe と表記され、「テラバイト実効」と発音されます。これは、レプリケーション、容量使用率、およびデータ削減 (圧縮、重複排除など) 後に使用可能なストレージ スペースです。プロット圧縮を使用した Chia ファーミングの場合、実効容量を ak=32、101.3GiB / 108.8GB、約 43 億プルーフのスペースに正規化します。チア農業では、報酬は減圧後の有効容量で獲得されるため、TBe は農家が報酬を見積もるために使用する必要がある数です。ユーザーはさまざまな K 値を持つプロットが混在するため、報酬を推定するためにプロットの数だけでは十分ではありません。

圧縮の TCO – フリー ランチなし
優れたスプレッドシートがなければ、JM ブログの投稿にはなりません。農業従事者にとっての基本的な問題は、どの圧縮レベルを選択するかということです。最高の圧縮レベルでプロットして最大のストレージ効率を得て、それによって最大の報酬を得たいと思うかもしれませんが、ファーミング中にプロットを解凍するための計算オーバーヘッドがあり、ベースライン ファーミングと比べて余分なエネルギーが必要になります。Disk io は解凍の影響をあまり受けません。アウトプットに実質的に影響を与えるインプットは、
- 圧縮レベル
- プロット数
- 農業システムの計算能力
- 電力コスト ($/kWh)
- ベースライン電力効率 (システム全体の W/TB)
ファーミングのコンピューティングとエネルギーのオーバーヘッドを見つけるには、ファーマーは特定の圧縮レベルで単一のプロットをプロットし、プルーフ オブ スペース ツールを使用して、プルーフの品質チェックと、指定された数のプルーフの完全なプルーフ オブ スペースを実行する必要があります。このツールは約 9 秒間ループして、Chia の標識ポイント時間をシミュレートできます。サイネージ ポイントごとのプルーフの数にフィルターを掛けて、特定のシステムで特定の量のコンピューティングでファーム可能なプロットの数を取得します。CPU が圧倒され、プルーフ オブ スペースの解凍に時間がかかりすぎる場合は、圧縮レベルを下げる必要があります。総所有コストと ROI を正確に把握するには、電力とエネルギーを測定する必要があります。これは、圧縮レベルが高くなると、エネルギー消費と運用コストが増加するためです。
このスプレッドシートを使用して、特定のファーム サイズで計算およびエネルギー オーバーヘッドの見積もりを測定した後、最適な圧縮レベルを見積もることができます。
よくある質問
Q: なぜ圧縮されたプロット形式をリリースするのですか?
A: 技術を構築できる場合、誰かがそれを構築します。圧縮された区画の場合、少数の農家だけがこの技術にアクセスできれば、他の誰よりも有利になります. 無料でオープンソースの圧縮プロット形式をリリースすることで、誰もが最先端の技術を使用してプロットを作成できるようにします。誰も他の誰よりも戦術的に有利になることはありません。
Q: 圧縮プロットを使用する必要がありますか?
A: いいえ。圧縮はオプションです。
Q: 既存のプロットを圧縮できますか?
A: いいえ。技術的には可能ですが、単に新しいプロットを作成するよりも多くの時間とエネルギーが必要です。
Q: 圧縮プロットを使用しないと不利になりますか?
A: 現在、農業には平等があります。誰もが同じプロット形式を使用しているため、より多くの報酬を獲得するには、より多くのプロットを保存するしかありません。再プロットしないことを選択した場合、他の人が再プロットするにつれて、プロットを保存するディスクの数が同じであっても、Netspace の相対的なシェアはゆっくりと減少します。これにより、他の誰よりもわずかに不利になります。ただし、再プロットに余分な時間や電力を費やさないことも意味します。決定は完全にあなた次第です。
Q: 将来、プロットをさらに圧縮するプロット形式が追加される予定はありますか?
A: ありそうもない。2020 年に現在のプロット フォーマットをリリースしたとき、適切なタイミングとテクノロジーによって特定のトレードオフと改善が可能になることはわかっていました。しかし、今日、私たちは圧縮の理論的限界に近づいています。プロットをわずかなパーセンテージ以上でさらに圧縮する新しい形式が表示される可能性はほとんどありません。投稿で、減圧をオフロードする機能があれば、限界に近づくいくつかのレベルを追加する可能性が高いと述べました.
Q: Bladebit Beta 圧縮が最終的なプロット形式になりますか?
A: Chia クライアントは、ベータ プログラムでリリースされたバージョンをサポートします。プロット形式には、特定されたマイナーなアルゴリズム最適化のための最適化の ~1-2% が追加されており、ある時点でリリースされる可能性があります。10 年の後半に向けて SSD でのファーミングが実行可能になると、HDD に比べてフラッシュのレイテンシが低いため、プロット形式が再び変更される可能性があります。これらの小さな変更は、実装したコンピューティング スペースのトレードオフのように、プロット サイズの大幅な減少を見ると、利益が減少します。
Q: プロットの作成に使用するハードウェアは重要ですか?
A: 同じk値と圧縮レベルでBladebit によって作成されたすべてのプロットは、それらの作成に使用されたハードウェアに関係なく、同じように見えます。
Q: k-32 プロットを引き続き使用できますか?
A: はい。現時点では、最小kを増やす予定はありません。この値を引き上げる予定がある場合は、少なくとも 1 年前に通知されます。
Q: プロットの圧縮レベルを組み合わせて一致させることはできますか?
A: はい、プロットの圧縮レベルを組み合わせることができます。農業従事者は、ツールを使用して圧縮レベルのベースラインを設定し、オーバーヘッドを計算し、電力が農業の収益性にどのように影響するかを理解する必要があります。
Q: プロットを圧縮する方法はヘルマン アタックと呼ばれますか?
A: 同様の方法です。時空間トレードオフのビット ドロップ法とヘルマン アタックはどちらも、1 つまたは複数のテーブルを削除することで機能しますが、ヘルマン アタックではエントリの再作成がはるかに複雑になり、プロットに時間がかかります。私たちが使用する方法は、削除されたテーブルをディスクに書き込むためのプロット時間を短縮します。
Q: いつリリースされますか?
A: 圧縮プロットをサポートする Bladebit Diskplot と Ramplot は機能が完成しており、内部テストが行われています。圧縮されたプロットをファーミングする Chia クライアントのサポートは積極的に終了しており、機能が完成したら、クロスプラットフォームと OS のサポートを含むパッケージ全体をベータ プログラムにリリースします。
Q: 圧縮プロットの作成にかかる時間は短くなりますか?
A: 計算スペースのトレードオフに使用している方法の利点は、一部のテーブルを最終的なプロット ファイルに格納する必要がなくなり、プロット時間がわずかに短縮されることです。
Q: これは、ハーベスターとして実行するラズベリー パイにどのような影響を与えますか?
A: エネルギーと計算能力が低いファーマーとハーベスターは、より低いレベルの圧縮 (レベル 1 ~ 4) で実行できます。ファーミングされるストレージの量は、コンピューティング オーバーヘッドに大きな影響を与えます。集中型ファーマーがリモート ハーベスターからプロットを解凍できるようにするハーベスター プロトコルの機能強化を開発し、エネルギー効率を改善し、低コスト/計算ハーベスター サポートを可能にします。
Q: すごいね!ハーベスター プロトコルに対するこれらの機能強化はいつリリースされますか?
A: 機能の優先度と計画に関する最新情報については、roadmap.chia.net をいつでも確認できます。また、当社の製品チームにコメントを残すこともできます。
チアの未来を描く
Chia チーム – 2023 年 1 月 20 日
最近、チアでの計画と農業の将来について、多くの興奮と混乱がありました. プロットは本当に圧縮できますか? GPU プロットは可能ですか? Chia は、ビットコインのようにエネルギーを浪費する Proof-of-Work チェーンに変わりつつありますか? YouTube のクリックベイトはコミュニティを追い越しましたか? 記録をまっすぐに立てましょう。
プロット圧縮
既存の Chia プロットは既に圧縮されています。ただし、プロットから一部のデータを省略し、ファーミングに必要なときにオンザフライで生成することで、さらに「圧縮」することができます。2020 年半ばに最終的なプロット形式をリリースして以来、このようなさらなる最適化が可能であることはわかっていました。しかし、当時はテクノロジーの準備が整っていなかったため、他のことを優先しました。主にブロックチェーンの立ち上げです。
今日に至るまで、より容易に利用できるテクノロジーと一部の勇敢なコミュニティ開発者の組み合わせにより、この機能のロックが解除されました。ただし、重要な要素は、プロットの圧縮レベルと、圧縮されたプロットを使用してファーミングするために必要な追加の計算作業 (CPU または GPU) との間にトレードオフがあることです。
この時空間のトレードオフは非線形です。特定のポイントを超えてプロットを圧縮しても、プロットはわずかに小さくなるだけですが、ハーベスターがその場でデータを再作成するには、指数関数的に多くのリソースが必要になります。プロットをどれだけ深く圧縮できるかについて、技術的な限界に近づいています。ここから先は、圧縮の段階的な小さな改善のみが予想されます。
チアをグリーンに保つことに尽力しています。新しいプロット形式はこれを変更しません。最高の圧縮レベルでも、ファームに必要な少量の余分なエネルギーは PoW とは異なります。さらに、プロット圧縮はオプションであり、今後もオプションのままです。
Chia プロットがどのように機能するか、これがどのように可能であるか、圧縮プロットを使用するかどうかを決定する方法、およびセットアップに適した圧縮レベルについて詳しく説明するために、私たち自身のJM Handsがこれを補足する優れたブログ投稿を書いています.
GPU プロッティング (およびファーミング)
さまざまなハードウェアがプロット用に常に利用可能であり、古いコンピューターと追加のストレージがあれば誰でも Chia プロットを作成できます。プロットの作成に使用されるハードウェアに関係なく、結果は常に同じです。唯一の違いは、プロットが作成される速度です。
何年にもわたって数多くの新しいプロッタが登場してきたため、一貫して要求されるのは CPU でした。しかし、今はそれさえも変わりつつあります。まもなく、GPU でプロットを作成できるようになります。
GPU プロットの素晴らしい点は、高速であることです。わずか 80 秒で作成された k-32 プロットを既に確認しており、今後数か月でプロット作成時間がさらに短縮されると予想されます。Akash などのサービスからプロットをダウンロードする初心者から、最新かつ最高のハードウェアを備えたクジラまで、誰もが自分のファームを迅速かつ効率的に拡張できます。
ローエンドのハードウェアを念頭に置いて Chia ファーミングを設計し、そのコミットメントに固執しています。控えめな Raspberry Pi でさえ、少量のプロット圧縮でファームできます。最高レベルの圧縮でも、CPU をファーミングに使用できるはずですが、GPU ファーミングも実行可能になり、おそらく好ましいものになる可能性があります。正確な詳細を推測するのはまだ時期尚早ですが、GPU を使用したファーミングが PoW のエネルギーを消費するほどではないという予測に自信を持っています.
GPU プロッティングとファーミングのすべての技術的側面を深く掘り下げるために、JMは別の素晴らしいブログ投稿を書いています。
プロット フィルターを削除する
高速なプロットは素晴らしいことですが、誰かがあまりにも速く (28 秒未満で) プロットを作成でき、経済的に (これについては後で説明します) 作成できる場合、ディスクに保存するのではなく、オンザフライでプロットを継続的に作成および破棄できます。これはプロット グラインディングと呼ばれ、セットアップはプルーフ オブ ワークに似ています。
今のところ、GPU を使用していてもプロットの作成時間が遅すぎるため、プロット グラインドは実行できません。しかし、区画整理は来年かそこらで技術的に実現可能になる可能性が高い. ただし、良いニュースは、たとえそれが可能になったとしても、プロットをグラインディングすると、プロットをディスクに保存するよりもはるかに多くの費用がかかるということです。その結果、農業従事者は、ネットワークを意図したとおりに使用した場合よりも収益が少なくなるため (もしあったとしても!)、区画整理を選択することを経済的に思いとどまらせることになります。
それでも、区画整理は年を追うごとに安くなります。Bram は最初から、プロットのすりつぶしを完全に防ぐことはできないことを知っていました。そのため、私たちの設計では、ネットワークを時折調整することで、それを不経済に保つように努めています。不経済なままであることを確実にするために、今後数年間でプロット フィルター (プロット グラインドの利点を増幅する) を段階的に削減する CHIP を作成しました。この提案の技術的な詳細はCHIPに記載されており、プロット グラインドの経済性 (またはその欠如) については、 GPU プロッティングに関するブログ記事で詳しく説明されています。
次のステップ
Chia Network Inc. は、プロット圧縮をサポートするために、Bladebit の新しいバージョンを数週間以内にリリースする予定です。プロッターはすでにテストの最終段階にありますが、ファーマーの作業はまだ完了していません。ファームできないプロットを作成してもほとんど意味がありません。私たちの仕事に加えて、いくつかのコミュニティ開発者は、madMAx の Gigahorse プロッター/ファーマー ソフトウェアなど、独自の圧縮ツールもリリースしています。やがて、ニーズに合った最適なプロッタを選択できるようになります。
圧縮されたプロットを使用するかどうかの決定、および適切な圧縮レベルは、個人的で微妙な違いがあります。考慮すべきパラメータがいくつかあります。設定によっては、圧縮を深くしすぎると、獲得できるファーミング報酬が少なくなる場合があります。しかし、ほとんどの農家は、より低いレベルの圧縮から恩恵を受けるでしょう. プロットの圧縮に関するブログ投稿には、情報に基づいた決定を下すための詳細が含まれています。
最終的に、これらは遅かれ早かれ Chia にもたらされることを常に知っていた進歩です. 問題は、場合ではなく、いつでした。「いつ」はたまたま予想よりも早かったのですが、それほど驚くことではありませんでした。これがどうなるか楽しみです。Chia は依然として、最も安全で、コンプライアンスに準拠し、持続可能なブロックチェーンの 1 つであり、PoST の主張を堅持しています。
よくある質問
Q: なぜ圧縮されたプロット形式をリリースするのですか?
A: 技術を構築できる場合、誰かがそれを構築します。圧縮された区画の場合、少数の農家だけがこの技術にアクセスできれば、他の誰よりも有利になります. 無料でオープンソースの圧縮プロット形式をリリースすることで、誰もが最先端の技術を使用してプロットを作成できるようにします。誰も他の誰よりも戦術的に有利になることはありません。
Q: 圧縮プロットを使用する必要がありますか?
A: いいえ。圧縮はオプションです。
Q: 圧縮プロットを使用しないと不利になりますか?
A: 現在、農業には平等があります。誰もが同じプロット形式を使用しているため、より多くの報酬を獲得するには、より多くのプロットを保存するしかありません。再プロットしないことを選択した場合、他の人が再プロットするにつれて、プロットを保存するディスクの数が同じであっても、Netspace の相対的なシェアはゆっくりと減少します。これにより、他の誰よりもわずかに不利になります。ただし、再プロットに余分な時間や電力を費やさないことも意味します。決定は完全にあなた次第です。
Q: 既存のプロットを圧縮できますか?
A: いいえ。技術的には可能ですが、単に新しいプロットを作成するよりも多くの時間とエネルギーが必要です。
Q: CPU や GPU を使用してプロットをプロット/ファームするのは、Chia をプルーフ オブ ワークにするためだけのものではありませんか?
A: まったくありません。ここでは、見ている圧縮のレベルに応じて、比較的小さなパーセンテージの余分な労力について話しています。(表とグラフの完全な内訳については、上記のリンク先のブログ投稿をチェックしてください)。リターンの減少は、実際の PoW マイニングに匹敵するもので、CPU または GPU が完全に実行されるポイントに到達するずっと前に、それ以上の圧縮の利点を無効にしてしまいます。いくつかのデータをドロップしてプロットを生成する速度を合計し、ファーミング時のルックアップ中にそのデータの計算を処理することを考慮に入れると、正味の差は最初に考えるよりもさらに小さくなります. さらに、プロットは無限のアクティビティではありません。利用可能なドライブがいっぱいになるまでのみプロットし、極端なエッジ ケースのクジラは別として、
Q: プロットの作成に使用するハードウェアやプロット ソフトウェアは重要ですか? A: 同じk値と圧縮レベルで
Bladebit によって作成されたすべてのプロットは、それらの作成に使用されたハードウェアに関係なく、同じように見えます。ただし、コミュニティで作成されたプロッターが異なれば、それらを使用する際の農家の要件も異なります。あなたのマイレージは異なる場合があります。
Q: k-32 プロットを引き続き使用できますか?
A: はい。現時点では、最小kを増やす予定はありません。この価値を引き上げる意図がある場合は、少なくとも 1 年前に通知するというスタンスを維持します。
Q: プロットの圧縮レベルを組み合わせて一致させることはできますか?
A: はい、プロットの圧縮レベルを組み合わせることができます。農業従事者は、ツールを使用して圧縮レベルのベースラインを設定し、オーバーヘッドを計算し、電力が農業の収益性にどのように影響するかを理解する必要があります。